AI insights
- The article argues that transformation failures usually build slowly through human problems like weak skills, poor collaboration, thin support, and staffing gaps long before dashboards show risk.
- It cites research showing many transformations and large IT programs miss goals, run late, go over budget, and deliver less value than promised.
- TCE is presented as an early warning system that helps leaders spot capability gaps, weak handoffs, and support issues while they are still cheaper to fix.
- The piece highlights common hidden risks such as missing AI skills, cross-team friction, low business acumen, and heavy dependence on a few overloaded specialists.
- It also warns that blame culture delays honest reporting, causing teams to hide fatigue, blockers, and trust problems until the damage is expensive.
- The core message is that leaders need earlier visibility into human signals, not more dashboards, to change course before delivery failure hardens.
In the age of AI, the real delivery risk is still human: capability, collaboration, support, and staffing problems that surface too late.
Most failed transformations do not explode. They sag.
A deadline moves. Communication gets sloppy. The team says they are “mostly on track,” but everyone feels the drag. By the time the dashboard shows budget pressure or schedule risk, the real damage has already been done.
That is the part most leaders miss.
BCG reports that 70% of transformations fail to achieve their initial goals. That is one problem. A separate body of research on large IT programs from McKinsey & Company shows another: they often run over budget, slip in time, and deliver less value than promised. Different studies, different lenses, same uncomfortable truth. Failure usually builds upstream before it becomes visible in the usual delivery metrics.
That is where the Team Capability Engine (TCE) has a real lane. Not as a replacement for project management, architecture governance, QA, DevOps, incident tooling, or portfolio control. And not as a magic answer to project failure. Its value is narrower and more useful than that: TCE helps leaders see capability, collaboration, support, and staffing issues earlier—while those problems are still cheap to fix.
1. The skills gap does not show up on a Gantt chart
Why this matters: Tech leaders keep funding AI programs as if the hard part is the model. In practice, the hard part is whether the team has the skill coverage to use the technology well.
The gap is not theoretical anymore. In the World Quality Report 2025, 50% reported that their organizations lack AI/ML expertise. That means an initiative can look well planned on paper while quietly depending on talent the team does not actually have.
This is where projects begin to lie. The roadmap looks clean. The milestones look reasonable. But inside the work, people are guessing, over-relying on a few specialists, or learning under a deadline.
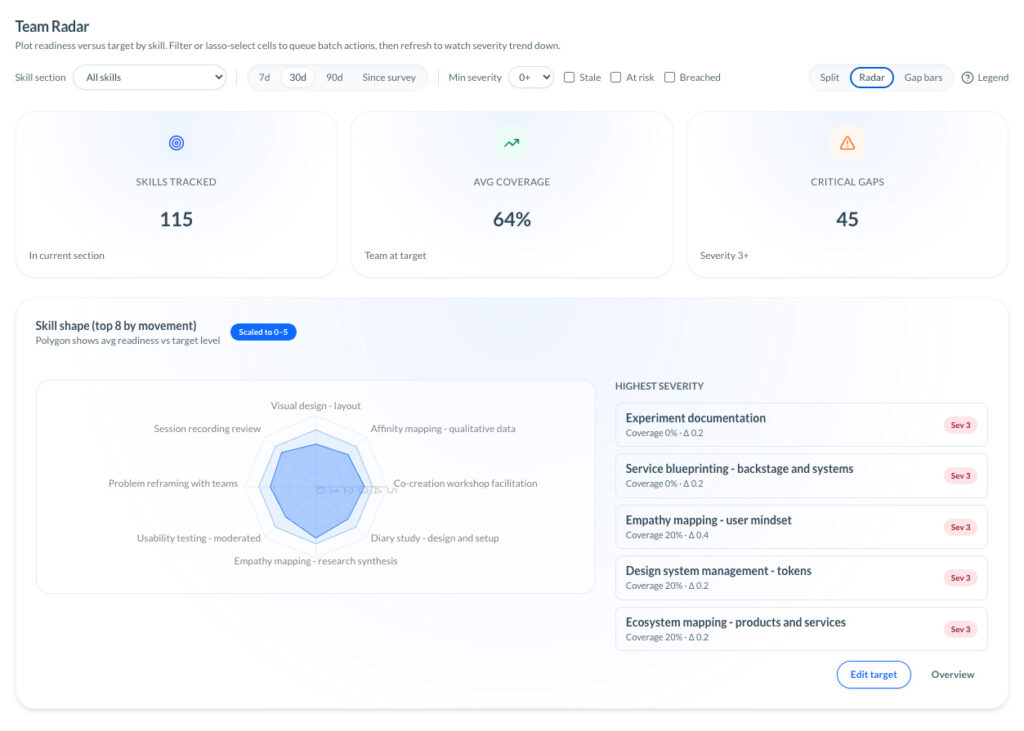
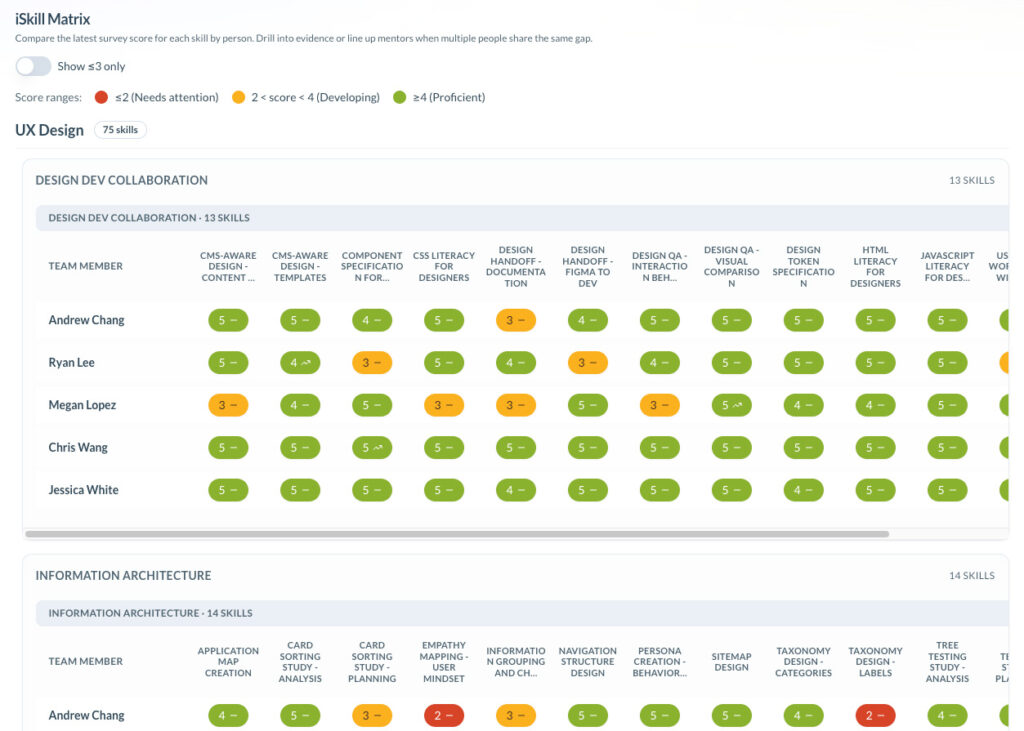
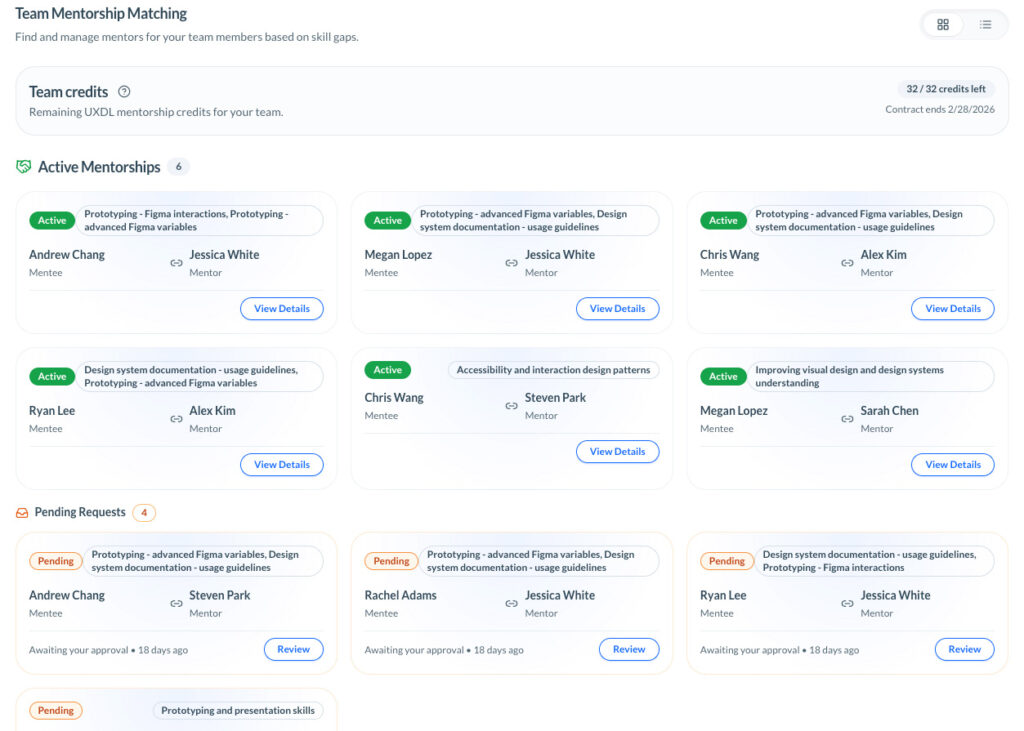
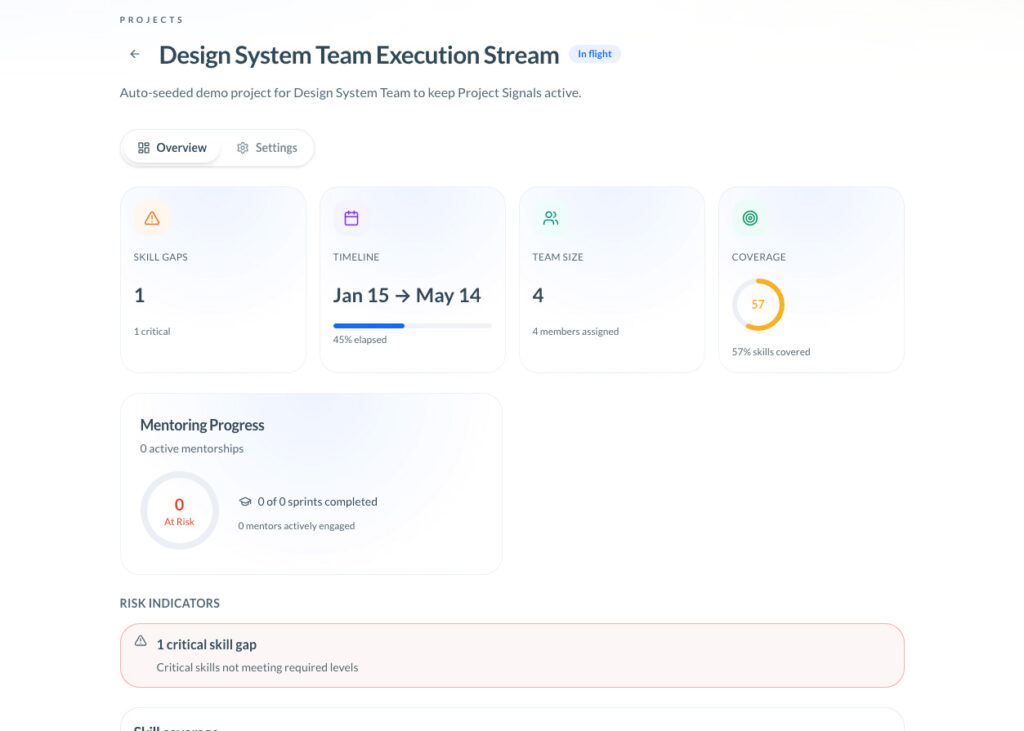
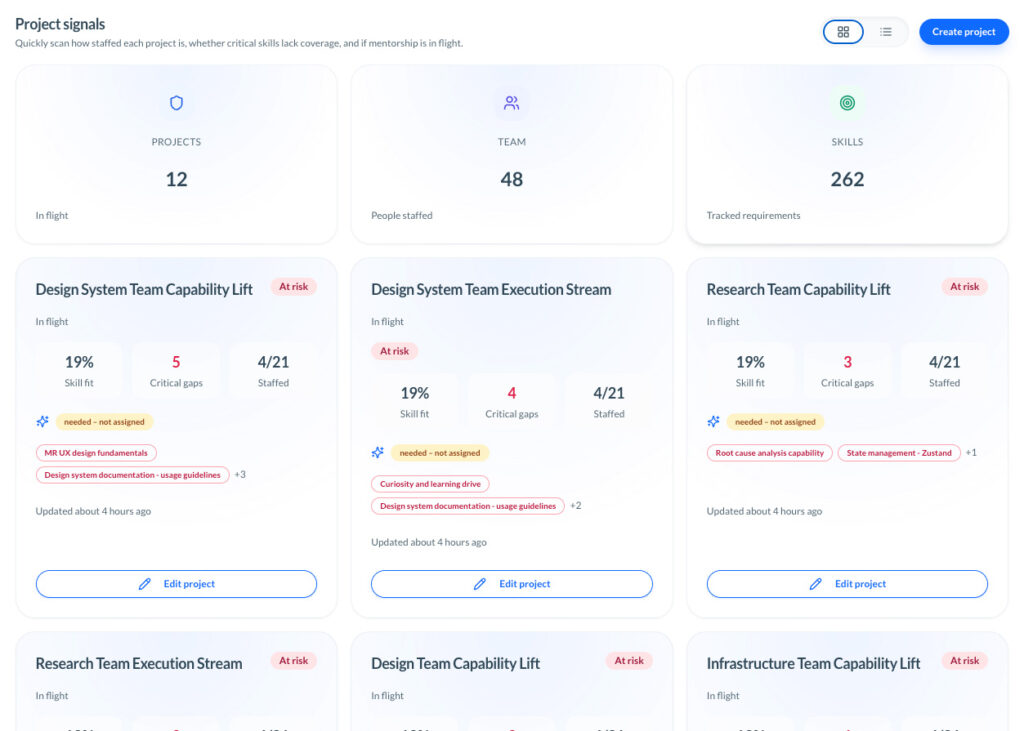
A tool like TCE is useful here because it surfaces the capability side of execution earlier through recurring survey cycles, not after a miss. Project Signals (capability risk based on project skill coverage), Team Radar (target-gap views), and Learning Goals expose where a team lacks coverage, where support is too thin, and where coaching or staffing is needed before the shortfall turns into rework.
2. Most delivery friction lives in the handoffs
Why this matters: Leaders love to ask which team is behind. The better question is what is breaking between teams.
Some of the most stubborn failure causes are not owned by one department at all. They sit in the space between product and engineering, engineering and QA, delivery and leadership. Research by Lehtinen et al. (2014) on software project failure found that, on average, 50% of causes were “bridge causes”—problems that sit between teams rather than inside one function. Lack of cooperation and weak backlogs showed up again and again.
That sounds abstract until you have lived it. Product thinks engineering has enough detail. Engineering assumes priorities are settled. QA arrives late and finds the work unstable. Everyone is busy. Nobody is aligned.
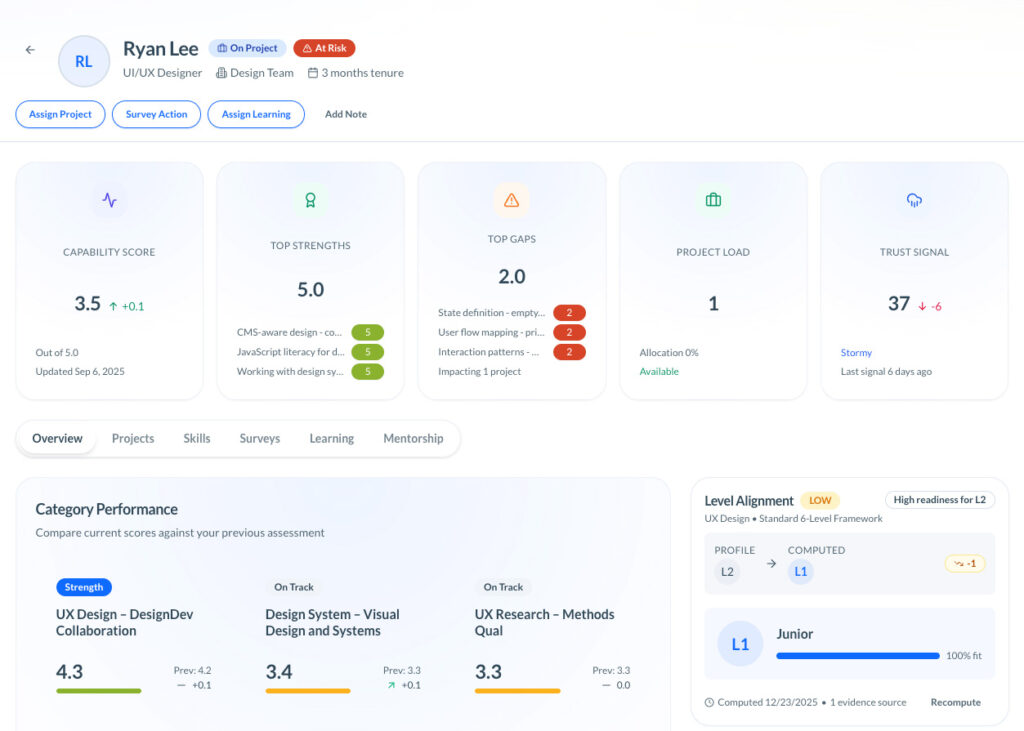
Traditional status reporting usually blames the visible bottleneck. TCE is more useful when it catches the invisible one: weak collaboration, fuzzy role boundaries, slow decisions, or uneven support across the team. That is exactly where TCE’s Team Radar, Project Signals, Member 360 (the detailed manager view), and recurring survey cycles are useful: they make the seam visible before the bottleneck becomes political.
3. Strong delivery still fails without business acumen
Why this matters: Teams can ship the thing they were asked to build and still miss the point.
This is one of the quieter problems in tech delivery. Technical skill gets people into the room. Business acumen is what keeps the work tied to real value once they are there.
PMI’s 2025 research found that only 18% of project professionals demonstrate high business acumen. The number matters because it shows how few delivery professionals are equipped to connect execution to business value.
That gap shows up in familiar ways. Teams optimize for output instead of outcome. Features ship because they were requested, not because they change a business result. Work gets done, but not enough of it matters.
This is another place where TCE can help without pretending to do everything. Structured mentorship routing, Learning Goals, and DoT sprints (structured mentorship sprints tied to growth and evidence) can strengthen the judgment layer around execution. Not just “Can the team build it?” but “Do they understand why it matters, what tradeoff they are making, and what success should look like?”
4. Overloaded specialists are a hidden delivery risk
Why this matters: A team can look fully staffed and still be one vacation, one resignation, or one bad week away from delay.
Anyone who has worked in complex delivery has seen the pattern. On paper, the team is covered. In practice, too much knowledge sits with too few people. One engineer owns the integration logic. One architect understands the legacy dependencies. One product lead carries the customer context in their head.
That fragility rarely shows up in standard reporting. The sprint board still moves. The status call still sounds fine. But the real system depends on a handful of overloaded specialists absorbing risk for everyone else.
In TCE terms, this is weak coverage, missing coverage, or overloaded people hidden inside a project that looks staffed on paper.
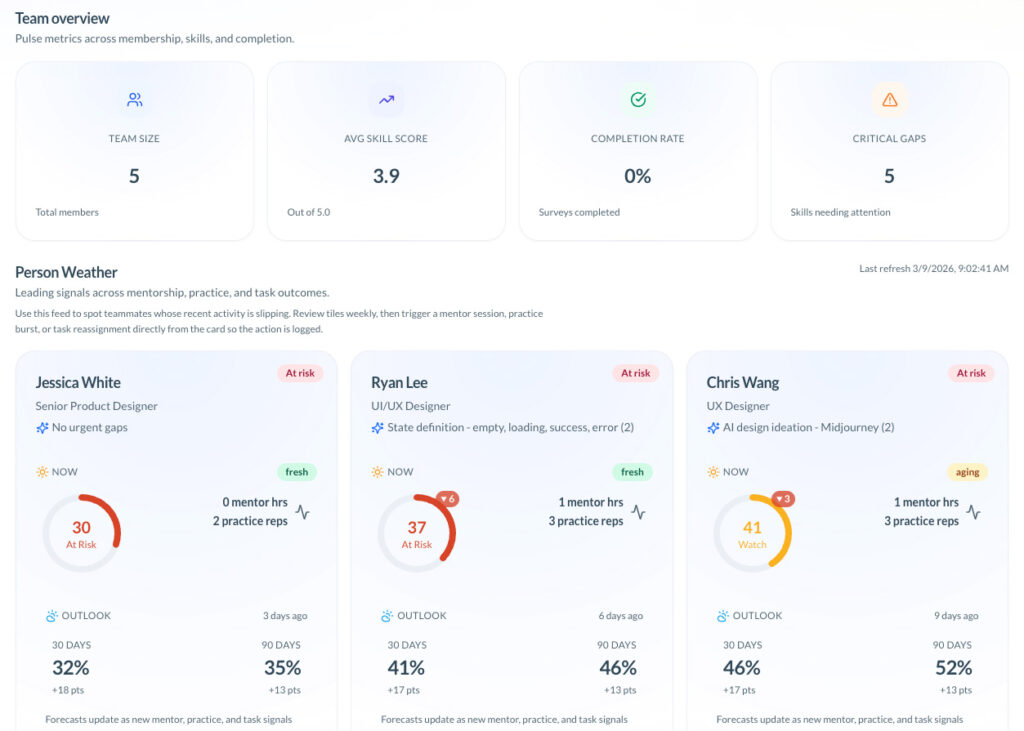
This is where TCE fits cleanly. The iSkill Matrix (a person-by-skill comparison view), Project Signals, and Member 360 help leaders spot thin coverage, rising support strain, and growing dependence on a few key people before that pressure becomes missed work or silent burnout.
5. Blame culture hides risk until it is expensive
Why this matters: A dashboard is only as good as the honesty feeding it.
Google’s SRE guidance on Postmortem Culture puts it plainly: “An atmosphere of blame risks creating a culture in which incidents and issues are swept under the rug.” That is not a soft cultural concern. It is a reporting problem, a learning problem, and eventually a delivery problem.
When people think bad news will be punished, the signal gets delayed. Status stays green a little too long. Risks are softened in meetings. Problems are framed as isolated when they are already systemic.
This is one of the strongest use cases for TCE. Recurring surveys, Person Weather (manager-facing signals summarizing individual risk or support needs), Member 360, and Project Signals can help surface the human truth earlier: low trust, uneven support, rising fatigue, hidden blockers, or a team that has stopped speaking plainly. Once those signals are visible, leaders have a chance to intervene before denial turns into cost.
Conclusion
Most leaders do not fail because they lack dashboards. They fail because their dashboards see the damage too late.
TCE is built around a simple operational loop: gather signals, interpret them, decide what to do, act, and measure whether things improved.
Not that it replaces project controls. Not that it governs architecture. Not that it rescues every bad transformation. But that it helps leaders see invisible skill gaps, weak handoffs, overloaded specialists, and low-trust reporting before the usual metrics catch up.
If a transformation is going off the rails, the question is rarely, “Do we have a plan?” The harder and better question is, “Can we see the human signals early enough to change course?”
If you are leading change, that is not a culture note. It is an operating warning.
Key takeaways
- The earliest signs of failure are usually human: invisible skill gaps, weak handoffs, poor business judgment, overloaded specialists, and low-trust reporting.
- TCE is most credible when positioned as an early signal system for those risks, not as a replacement for delivery tooling.
- The earlier leaders can see capability and collaboration problems, the cheaper they are to fix.
Sources
This article draws on research and publications from Boston Consulting Group, McKinsey & Company, the World Quality Report 2025, PMI’s Pulse of the Profession 2025, Google SRE, Lehtinen et al. on software project failure causes, Bano et al. on requirements volatility, and CISQ’s 2022 report on the cost of poor software quality. Official source links are listed below.
- BCG: — https://www.bcg.com/publications/2020/increasing-odds-of-success-in-digital-transformation
- McKinsey — https://www.mckinsey.com/capabilities/tech-and-ai/our-insights/delivering-large-scale-it-projects-on-time-on-budget-and-on-value
- World Quality Report 2025 — https://www.sogeti.com/newsroom/world-quality-report-2025/
- PMI Pulse of the Profession 2025 — https://www.pmi.org/learning/thought-leadership/boosting-business-acumen
- Google SRE Postmortem Culture — https://sre.google/sre-book/postmortem-culture/
- Lehtinen et al. — https://www.sciencedirect.com/science/article/pii/S0950584914000263
- Bano et al. — https://pure.kfupm.edu.sa/en/publications/causes-of-requirement-change-a-systematic-literature-review/
- CISQ 2022 Report —https://www.it-cisq.org/the-cost-of-poor-quality-software-in-the-us-a-2022-report/






You must be logged in to post a comment.